People new to GPR-Arrays may think that array-data means more of the same thing. While this is partly true, there are other details, which, if considered, may ease the following stages of loading, processing, and interpretation of such data. This note aims to give a few hints on the data collection process and the subsequent management of collected data.
Data volume & density:
A small 3D project can hold some 5 GB of raw data in total. Not a big file by modern standards and easy enough to transfer using a memory stick. However, from a data security and processing perspective, it’s not wise to put all that data into a single file. Why? Cheap memory sticks are prone to file corruption during transfer, and this can be especially problematic if the data is in a single file and affected in any way not immediately noticeable by the operator.
Consequently, we recommend dividing even small projects into several parallel swaths (if possible). Also, the data volume is linear to the point distance, where half the point distance means double the data volume. It is usually of no benefit to collect data with a higher density than half the array channel spacing. Therefore, an array with 8 cm channel spacing equates to a point distance of 4 cm.
Navigation (in the data):
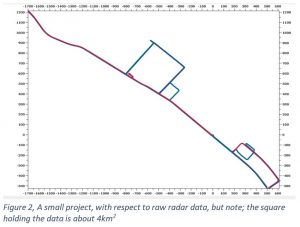
Figure 2 above shows a rather small project, as far as the raw radar data is concerned (approx. 4.5 GB), but the interpretation of a project like this means navigating from a km-scale down to a few meters, which puts quite a high demand on the processing software in use.
Positioning:
Positioning is, by far, one of the biggest talking points concerning the collection of array data. The use of high precision RTK-GPS is the most convenient and efficient positioning method and, for those reasons, takes preference over the use of total stations. However, this convenience becomes ineffective in areas where the signal is interrupted, e.g., by tree cover, tall buildings, or other overhead obstacles. Ultimately, it is the survey environment itself that determines the positioning method to use. For the descriptions that follow, it’s important to note that only RTK-fix is sufficient and that any loss of RTK-fix will cause extra work in the data management.
Sometimes, it’s possible to salvage a project with poor positioning; however, if the project is large with a high percentage of positioning errors, it may be more economical to re-survey with better positioning than to expend valuable time trying to fix it. Another important consideration that may later ease processing is the choice of positioning density during data collection, since too high a density may cause extra work. If you don’t have adequate control over the positioning process, it makes little sense to deploy to the field for data collection.

Sharp turns during data collection:
When collecting data in the field, it’s perfectly feasible to move the array in a manner that produces a sharp turn, or radius, along the collected swath. However, it’s a good idea to think about what this kind of maneuver will do to the subsequent data management. As illustrated in Figure 3, such a radius results in data that is significantly stretched along the outer perimeter, while being compressed along the inner perimeter. How this may affect the final image depends on how the data was collected. For example, if the point distance is set to 4 cm during data collection and 8 cm during interpolation, then it may work, but interpolating to the same bin-size as the point distance will definitively impact the data. Therefore, it’s important to consider such factors when planning a survey; if such turns are unavoidable, structure the survey so that data collected at these points is not the most important to the overall survey.

Holes in data
What happens with areas not covered by radar data? Well, modern software offers some ability to interpolate data into such empty spaces, but sometimes applying regularization may be a better choice. Regardless of the theoretical function employed, if the empty spaces are too big, no software can fix it, and those areas will be useless for interpretation. Another less obvious issue is that the interpolation/ binning function takes up memory space on the processing computer, but to what extent is dependent on the chosen processing software. A project like that shown in Figure 4 may be difficult to process due to the very large, unfilled, and closed areas. Of course, if opting to process by manually defining the areas to interpolate (‘chunking’), it may always be possible, but that’s rather old fashion.
Figure 5 shows a project with 4.5 GB of raw radar data, the same as the project shown above in Figure 2. However, the layout of this project is much better concerning data management, because it’s easy to navigate, has no sharp turns, nor holes in data.

Takeaway
Even with the best planning, a real-world project could contain data that is less than optimal. Therefore, when dealing with the data volumes from a modern GPR-array system, it’s always advisable to get rid of problematic data as early as possible. The next note in this series will deal with the topic of data QA/ QC and will discuss useful tools for the selection and management of data imports.
To download this article click here.
To learn more, explore Raptor page and Condor page